Orginaler Blog-Post: Normalität wiederhergestellt – Freifunk Kreis GT
Vorab: Sorry für die Unannehmlichkeiten und daß deren Behebung doch recht lange sich hinzog!
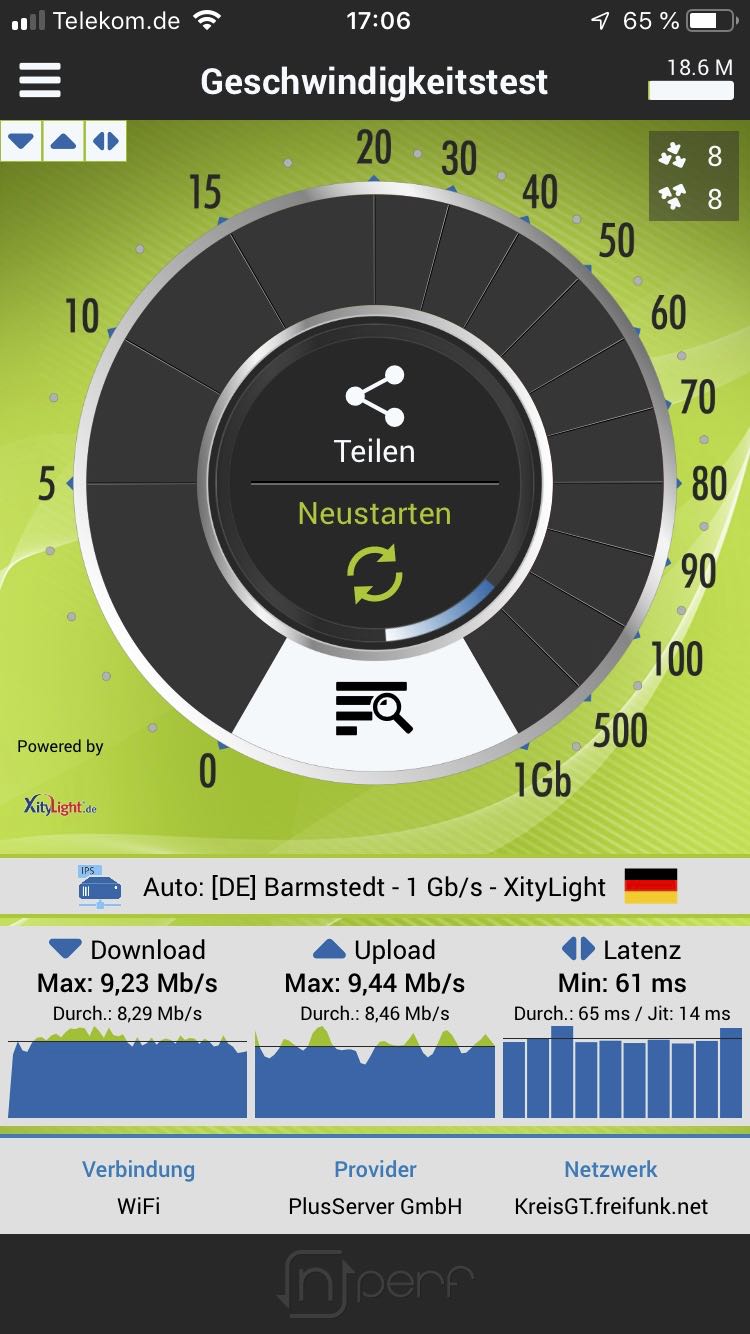
Aber immerhin: das Freifunk-Netz im Kreis Gütersloh müßte nun wieder grundsätzlich funktional und, im Rahmen der Betriebsparameter, auch wieder ›einigermaßen‹ performant sein — lies: deutlich besser als ›nur‹ ein Digitales Glas Wasser: auch der gelegentliche Videostream tut (wieder).
(Bild: »We’re back!«)
Das Gütersloher Mesh läuft nun auch wieder in Gütersloh, aus verschiedenen Gründen. IPv6 haben wir aktuell noch nicht wieder aktiviert denn, seien wir ehrlich, es tut (leider) auch ohne — aber öffentliche IPv6-Adressen kommen wieder, versprochen ;-)
Ab hier wird’s jetzt eher technisch; die Kurzfassung (»tl;dr«): über die Zeit haben sich verschiedene Fehler eingeschlichen wie auch die Netznutzung sich verändert. Es sind noch Nacharbeiten nötig, aber aktuell sehen die Werte als auch die Rückmeldungen vielversprechend aus.
Post Mortem
Was war passiert? Im Zuge der weiteren Optimierung des Setups – mehrere FF-Gateway-VMs auf mehreren Hosts (Hypervisoren) waren über eine Anzahl L2TP-Tunnel jeder mit jedem verbunden; dies sollte auf ein VXLAN-Interface pro Host, welches den batman-Traffic transportiert, umgestellt werden – wurde das FFGT-Netz final instabil. Auch vorher gab es schon vereinzelt bemerkte Probleme, u. a. dauerte die Namensauflösung ›schon immer‹ relativ lang. ›Meistens‹ tat es, aber gelegentlich war auch damals schon tote Hose. Parallel wurden generelle Änderungen am Setup der Gütersloher Serverfarm vorgenommen, um mit Plusserver in ein Peering-/Transit-Setup zu gelangen — da unser Freifunk-AS, 206813, sich mehr und mehr emanzipiert, machte das Sinn.
Vielleicht waren es zu viele Änderungen im zu kurzer Zeit, vielleicht auch die Ignoranz gegenüber den Anzeichen, daß etwas im Argen lag: letztlich war das Freifunk-Netz im Kreis Gütersloh ab Anfang Dezember 2018 »karpott« :-(
Daß der noch aus den Anfängen um 2014/15 stammende Statistikserver schon seit einigen Monaten kränkelte und keine vernünftigen Statistiken mehr aufzeichnete, tat sein übriges, um das Ausmaß der Probleme zu verschleiern.
Der, schwer vermittelbare, positive Effekt: da das Netz nun eh’ am Boden lag, konnte man auch mal disruptiver agieren (kompletter Neuaufbau von Gateways und Monitoring-Infra, was schon länger im Hintergrund vorbereitet wurde) und genauer hinschauen (weil weniger Traffic).
Gefunden wurde so unter anderem die Fehlkonfiguration, die im Mesh die Namensauflösung durch den Gateway-lokalen Nameserver vereitelte (lies: durch einen doppelte Anweisung startete jener erst gar nicht) — somit lief jede DNS-Anfrage erst einmal in den 2-Sekunden-Timeout, bis der nächste Nameserver befragt wurde.
Allerdings wurde bei einigen Gateways nur der lokale Nameserver in der DHCP-Antwort zurückgeliefert — eine weitere Fehlkonfiguration.
Überhaupt: DHCP. Dieses für die IPv4-Adresszuweisung notwendige Protokoll lieferten wir bislang von einem zentralen Server — weil andere Setups verschiedene andere Probleme haben. Leider wurden durch nur einseitig Änderungen die zum DHCP-Server ›gegrabenen‹ Tunnel dysfunktional — kurz gesagt, sie funktionierten nicht mehr und da sie auch nicht überwacht wurden, fiel dies nicht auf. In der Folge klappte die Adresszuweisung an manchen Freifunk-Knoten, an anderen nicht.
Beim ›Umzug auf die Grüne Wiese‹ (unserer Server in Hamburg) fiel dann auf, daß wenige Verbindungen die ›fastd‹-Prozesse negativ beeinflussen: dem Anschein nach gab es eine Handvoll Knoten, die signifikanten Datenverkehr abgriffen — was einerseits die einzige CPU der jeweiligen Gateway-VM überlastete (40+% CPU in der VM nur für den fastd-Prozeß), die summarischen bis zu 100 MBit/sec streßten auch den KVM-Teil dergestalt, daß der für das Netzwerk der Gateway-VM zuständige Prozeß ebenfalls mit 30-50% CPU-Last auf dem Hypervisor sichtbar wurde. Es ist allerdings bekannt, daß fastd ab ca. 40% CPU-Last anfängt, instabil zu werden, das zeigt sich gerne in sporadischen ›Hängern‹ im Datenfluß der Clients. Kurzum: auch hier bestand also Handlungsbedarf.
Das aktuelle Setup läßt die fastd-Prozesse auf dem Hypervisor direkt laufen, deren Interface wird per Linux-Bridge an die Gateway-VM weitergeleitet, in der das batman-adv-Kernelmodul für das Routing im Mesh sorgt. Hiermit wird mehr Rechenzeit für fastd bereitgestellt (durch weniger Overhead) und das Gesamtsystem vereinfacht (keine Quertunnel zu anderen Gateways mehr). Nachteil ist: derzeit läuft das ganze Mesh nur noch auf einem physischen Server, crasht der, steht das Netz wieder. Hier wieder Redundanz reinzubringen, ohne die Komplexität zu stark zu erhöhen, ist der nächste Schritt.
Abschließende, dringende, Bitte: wir informieren hier auf der Webseite und, teils granularer, im Forum nicht aus Langeweile über (auch) solche Probleme. Wir haben zwar eine Telefonnummer, die auf einem Anrufbeantworter aufläuft — aber wir können aus Kostengründen grundsätzlich nur Festnetznummern zurückrufen und diese auch erst nach, frühestens, 19 Uhr abends. (Darauf weist die aktualisierte Ansage nun auch wieder hin.) Kurzum: bitte eMail oder das Forum nutzen, und bitte auch dran denken, daß Freifunk eine ehrenamtliche Veranstaltung ist …

 Will be fixed tonight,
Will be fixed tonight,
{kind=link}