Bekomme gerade mit mehreren Endgeräten keine v4 Adresse. An verschiedenen Knoten. Hängt da was?
Yepp, leider. Eine unserer Kisten hat Probleme mit einer HDD, in Folge hängt sich der RAID-HA bzw. das Gesamtsystem ggf. auf.

Smart Array P400 in Slot 1
array A
physicaldrive 2I:1:1 (port 2I:box 1:bay 1, SAS, 146 GB, OK)
physicaldrive 2I:1:2 (port 2I:box 1:bay 2, SAS, 146 GB, OK)
array B
physicaldrive 1I:1:5 (port 1I:box 1:bay 5, SAS, 146 GB, OK)
physicaldrive 1I:1:6 (port 1I:box 1:bay 6, SAS, 146 GB, Predictive Failure)
physicaldrive 1I:1:7 (port 1I:box 1:bay 7, SAS, 146 GB, OK)
physicaldrive 1I:1:8 (port 1I:box 1:bay 8, SAS, 146 GB, OK)
physicaldrive 2I:1:3 (port 2I:box 1:bay 3, SAS, 146 GB, OK)
physicaldrive 2I:1:4 (port 2I:box 1:bay 4, SAS, 146 GB, OK)
Leider schaltet der RAID-HA die „vom Ausfall bedrohte“ HDD nicht aus und sie scheint in einem Modus zu sein, der bei bestimmten Zugriffen den SCSI-„Bus“ (den es bei SAS doch eigentlich gar nicht mehr gibt?!) stört oder den RAID-HA verwirrt oder was-auch-immer. Dieser Server ist Hypervisor für 9 VMs, darunter auch die Gütersloher IPv4-Exit-VM und die noch immer einzige DHCP-VM … Server ist erst mal wieder up and running, ich werde mal einen Plattenaustausch terminieren und parallel gucken, Last da runter zu nehmen.
Feb 11 16:33:52 s3 dhcpd: Adap-lease: Total: 4062, Free: 3011, Ends: -15822, Adaptive: 450, Fill: 25, Threshold: 75
Netz sollte erst mal wieder laufen.
Und hängt wieder 
Ich habs bemerkt.
Würde es nicht Funktionieren einen zweiten DHCP mit den selben Einstellungen außer der Ränge zu installieren? Evtl.noch mit einer Antwort Verzögerung das vorrangig der Hauptserver genutzt wird?
Klar, es gibt viele Alternativen zu einem SPOF. Hasse Zeit, sie umzusetzen? 
Gesagt ist immer einfacher als getan, kenne das Problem selber zu gut. Vor allem wenn die Primäre Aufgabe nur eine halbe Stunde dauert gibt es immer noch den Rattenschwanz.
(Bei mir würde vermutlich auch das tiefe wissen fehlen, so dass ich ein paar Böcke noch mit einbauen würde  )
)

So, Kiste rebootet wieder, hat sich beim Versuch, die Daten vom fraglichen RAID zu retten, wieder ins Knie geschossen. Neuer Versuch ohne “Recovery” durch den RAID-HA. Ist halt doof, wenn die Kiste während der Datenübetragung auf andere Server absemmelt
Hängt scheinbar wieder, keine v4 Adresse
Das wird heute noch weiter rumpeln, ein temporäres NFS-Share (backed by DRBD-RAID-1, professionellen Storage haben wir leider nicht) ist konfiguriert, derzeit werden VMs von lokalem auf shared Storage umkopiert, um dann auf andere Hypervisoren umgezogen zu werden. Sprich: mehrere Downtimes und Reboots der betroffenen VMs (im Grunde alle in GT — Operation Frühjahrsputz, wenn man so will) stehen noch an.
FTR, die defekte Festplatte wurde Anfang der Woche getaucht (Kudos an Ralf H.). Parallel wurde ein gespiegeltes NFS aufgesetzt, VMs darauf und auf andere Hypervisoren umgezogen, sodaß jene nun auch, falls ein Hypervisor defekt sein sollte, auf anderen wieder gestartet werden können. Parallel wird ein Framework aufgesetzt, welches derlei automatisieren hilft. Bilder zum Setup …
… vorher:
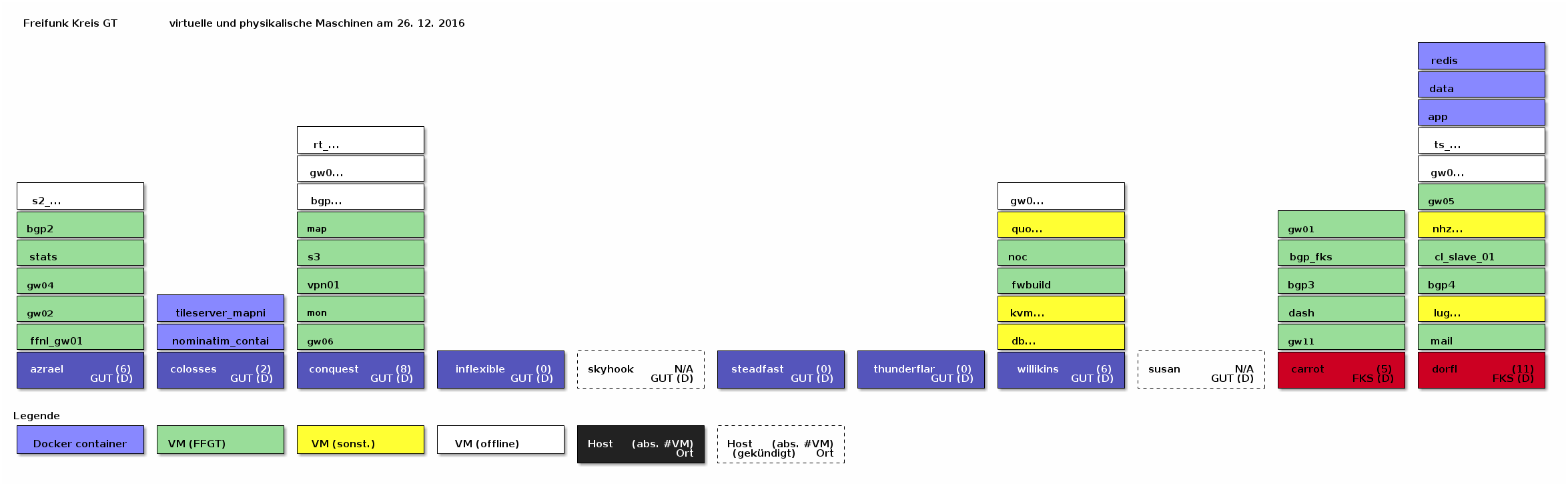
… aktuell:

Hakt die v4 Vergebe wieder?
Sie schien prinzipiell zu funktionieren, allerdings punktuell stark verzögert. Das sollte nach Änderungen in der Nacht zu Montag nun wieder (besser) funktionieren?
Habe gestern auch schon nichts gemerkt, aber da habe ich nicht explizit drauf geachtet.
Heute kann die IP auf jeden Fall sofort und das surfen klappt auch super. Mal heute Abend bei ein paar anderen Absagen testen
Danke für’s Feedback.
Ist »leider« mal wieder Zeit, an der Infrastruktur zu schrauben, da das Netz doch noch wächst. Und da dabei einige Altlasten entsorgt werden, rumpelt’s leider manchmal. Aber es ist Licht am Ende des Tunnels, denke ich
Gerade bei mir zu Hause geschaut, v4 kam direkt ohne Wartezeit. Netzwerk reagiert auch Flink. Bekomme aber gerade keine ULA, weder unter Windows noch unter Linux. (Wollte gerade auf einen anderen Knoten und hatte mich geweundert warum das nicht ging )
Hmm, ULA vergibt aber der lokale Knoten?!
Die FD42:…? Ist das keine Zentrale?
V4 Adressen wollen wieder nicht. Heute Mittag auch schon nicht, da über einen anderen AP
Über welches GW war der jeweilige Knoten verbunden?
Mist, habe ich nicht überprüft, und gerade funktioniert es wieder.
Aber hier ein Ausschnitt aus der Statusseite
33378-freifunk-a42bb0f43a87
There are 9 peers configured, of which 1 are connected:
mesh_vpn_event_peer_test01: not connected
mesh_vpn_backbone_peer_gw06: not connected
mesh_vpn_backbone_peer_gw03: not connected
mesh_vpn_backbone_peer_gw01: not connected
mesh_vpn_backbone_peer_gw04: not connected
mesh_vpn_backbone_peer_gw02: connected for 752962.084 seconds
mesh_vpn_event_peer_event02: not connected
mesh_vpn_event_peer_event01: not connected
mesh_vpn_backbone_peer_gw05: not connected
Also kann es ja nur GW2 gewesen sein.