FTR:
Aktueller Status:
- Forum von Berlin nach Hamburg umgezogen
- blackstar heruntergefahren (damit einzige andere VM dort, lt2p-ber01, ebenfalls down), siehe unten
- Routing hat noch »Optimierungspotential« — Traffic muß durch Nadelöhr Hamburg/IPHH, Durchsatz ggf. eher mau

- Routing-VM1 in GT (bgp-gut01) läuft z. Zt., Dauer unbekannt
- Das Setup braucht noch etwas Liebe …
Details:
root@blackstar:~# cat dmesg.preboot dmesg.postboot | grep enp1s0f.:
[Fri Aug 9 18:44:25 2019] netxen_nic 0000:01:00.1 enp1s0f1: renamed from eth1
[Fri Aug 9 18:44:25 2019] netxen_nic 0000:01:00.0 enp1s0f0: renamed from eth0
[Fri Aug 9 18:45:54 2019] net enp1s0f0: transmit timeout, resetting.
[Fri Aug 9 18:49:24 2019] net enp1s0f0: transmit timeout, resetting.
[Fri Aug 9 18:51:30 2019] enp1s0f1: Device temperature 94 degrees C exceeds operating range. Immediate action needed.
[Fri Aug 9 18:51:30 2019] enp1s0f0: Device temperature 94 degrees C exceeds operating range. Immediate action needed.
[Fri Aug 9 18:53:27 2019] net enp1s0f0: transmit timeout, resetting.
[Fri Aug 9 18:53:40 2019] netxen_nic 0000:01:00.0 enp1s0f0: speed changed to 0 for port enp1s0f0
[Sun Aug 25 11:21:38 2019] enp1s0f0: Device temperature 100 degrees C exceeds maximum allowed. Hardware has been shut down.
[Sun Aug 25 11:21:38 2019] enp1s0f1: Device temperature 100 degrees C exceeds maximum allowed. Hardware has been shut down.
[Sun Aug 25 15:13:20 2019] netxen_nic 0000:01:00.0 enp1s0f0: renamed from eth0
[Sun Aug 25 15:13:21 2019] netxen_nic 0000:01:00.1 enp1s0f1: renamed from eth1
[Sun Aug 25 15:21:06 2019] enp1s0f0: Device temperature 100 degrees C exceeds maximum allowed. Hardware has been shut down.
[Sun Aug 25 15:21:06 2019] enp1s0f1: Device temperature 100 degrees C exceeds maximum allowed. Hardware has been shut down.
==> 10G-Karte hat sich am Sonntag Vormittag mal wieder wegen – tatsächlicher oder virtueller Überhitzung – abgeschaltet, somit waren wir von allen Upstreams via Community-IX (DTAG, Strato, RETN, Vodafone, …) abgeschnitten. Da Tunnel zum unseren anderen Routern darüber liefen, war die Berliner Site weitgehend abgeschnitten. Ich hab’s zwar – im Kurzurlaub an der Nordsee – bemerkt und am frühen Nachmittag beheben können (Powerdown => Wiedereinschalten geht nur per Remote-Console, die aber nur per VPN erreichbar ist => Laptop notwendig) — zum Dank hat sich das System aber um 15:21 erneut ins Gehackte gelegt ![]()
Ausfall der Kiste in Berlin/der Zugänge zu Community-IX und BCIX alleine wäre noch nicht weiter tragisch, allerdings »spinnt« seit ein paar Wochen auch die Router-VM bgp-gut01 in Gütersloh, über die der Traffic von den Gütersloher Servern ins Internet geht. Jene hatte sich auch am Sonntag wieder mal eine Auszeit genommen, der Fallback über die eigentlich redundante VM bgp-gut02 hat nicht funktioniert, und somit war das Netz leider im Eimer, und das ziemlich gründlich ![]()
Der Traffic lief nun über unseren Server in Hamburg, mangels eindeutiger IPv4-Adressen dort (wir haben leider kein v4-Netz, was wir nur in Hamburg announcen könnten) und IPv6-Adressen in Gütersloh (leider läuft der BGP-Austausch mit Plusserver noch immer nicht) über den Tunnel durch den Uplink von IPHH, der allerdings aus 100 MBit/sec limited ist:
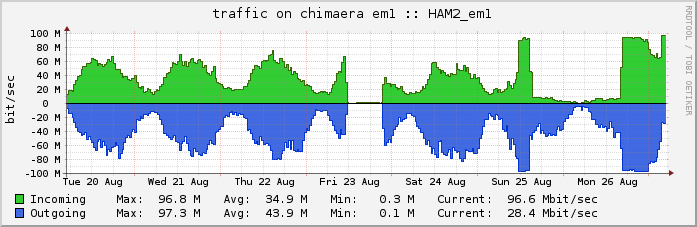
(Un-) Schöne Flatline … Im Normalfall reichen uns die gesponsorten 100 MBit/sec via IPHH, nach Wegfall von Berlin allerdings offensichtlich nicht mehr.
Weitere ~60 MBit/sec steuert derzeit mein AS49745 über den Server in Amsterdam bei (die Tunnel laufen via IPv6 und somit i. d. R. nicht über das IPHH-Kontingent):
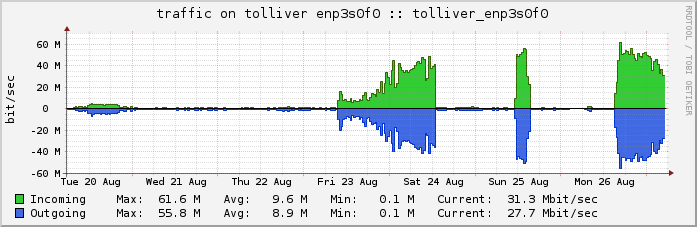
Anyway: Es sollte hoffentlich am Dienstag wieder besser laufen, sowohl Alt- als auch TNG-Netz liefen vorhin hier, Dienstag abend wird es weitere Routingoptimierungsversuche geben, Dienstag mittag einen Neustartversuch des bis dahin hoffentlich etwas abgekühlten Berliner Servers …
1 „Gefällt mir“
Vielen Dank für deinen Einsatz!
Moin.
Hat dies zufällig auch Auswirkungen auf die Region Müritz?
Wir bekommen zurzeit kein “sauberes Internet”: Heise und Google lassen sich aufrufen … die Map (muer/kreisgt) ist nicht erreichbar und einige Knoten sind Offline.
Cul8er
Matthias
Moin Matthias,
kann sein; bgp-gut01 hatte sich grade wieder ins Eisbett gelegt (VM hängt dann komplett und kommentarlos), hab’ 'n Reboot getriggert. Danke für die Info, neben “was geht” wäre auch “was geht nicht” hilfreich; es wird heute abend noch mal 'ne längere Session werden müssen, u. a. mit Austausch der bgp-gut01-VM und Umkonfiguration bgp-gut02, damit die VM auch wirklich übernehmen kann.
BTW: falls jemand “zufällig” routbare IPv4-Netze “über” hat: wir hätten Bedarf! :-?
MfG,
-kai
Dieses Thema wurde automatisch 10 Tage nach der letzten Antwort geschlossen. Es sind keine neuen Nachrichten mehr erlaubt.