Moin,
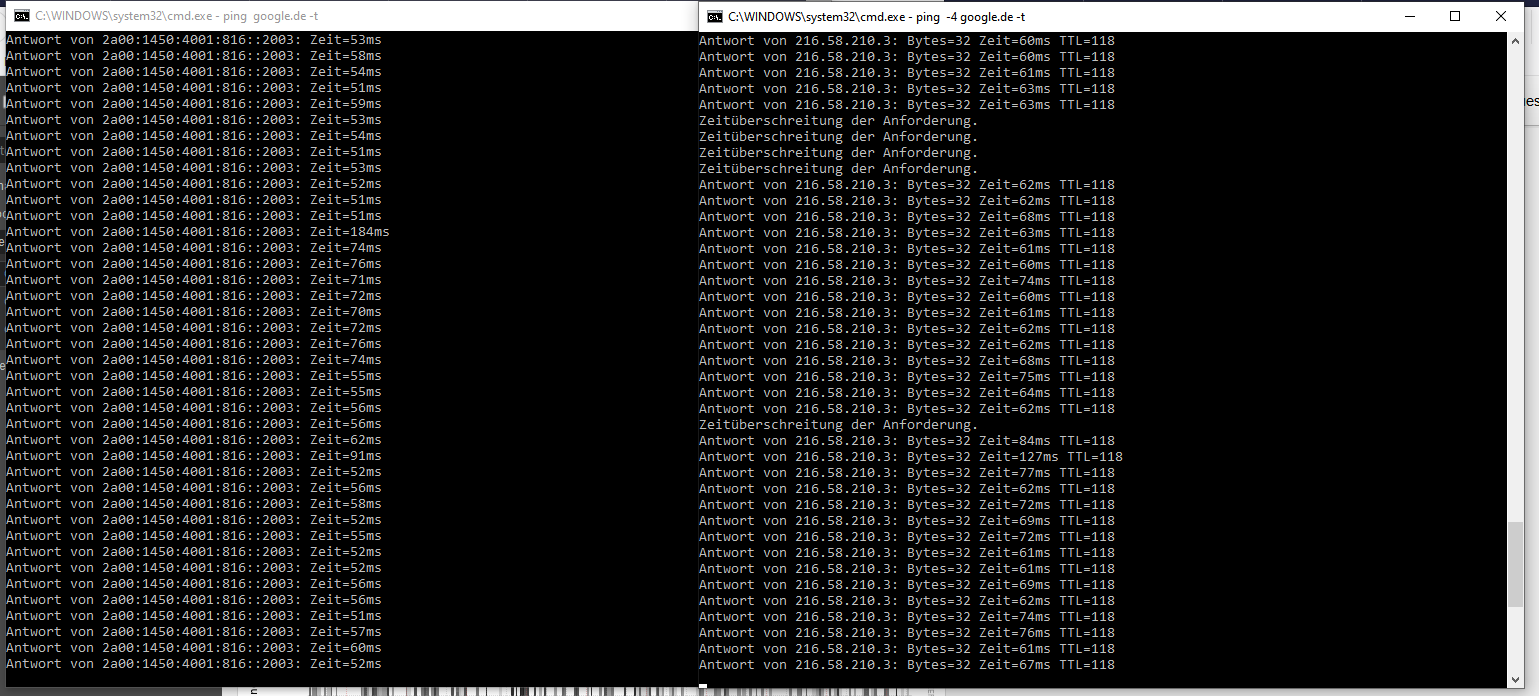
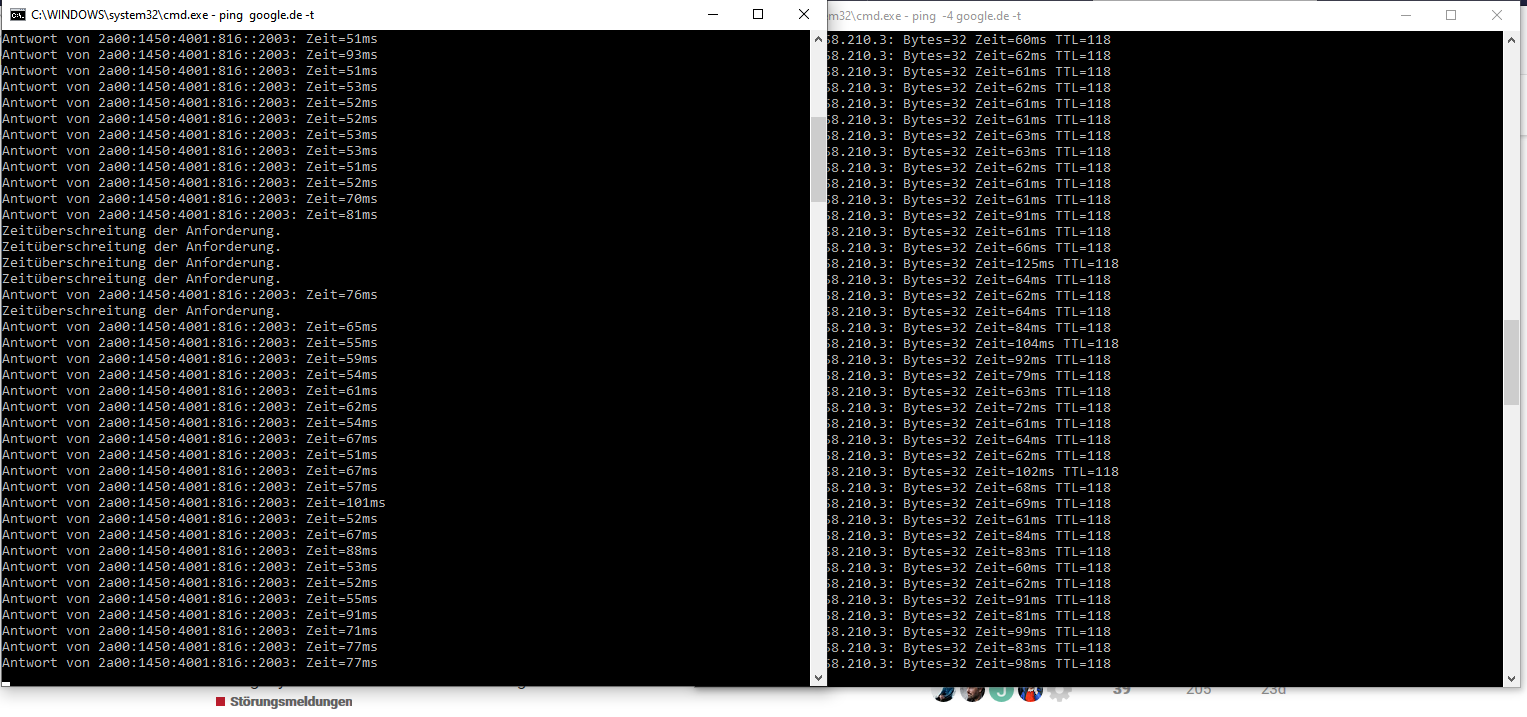
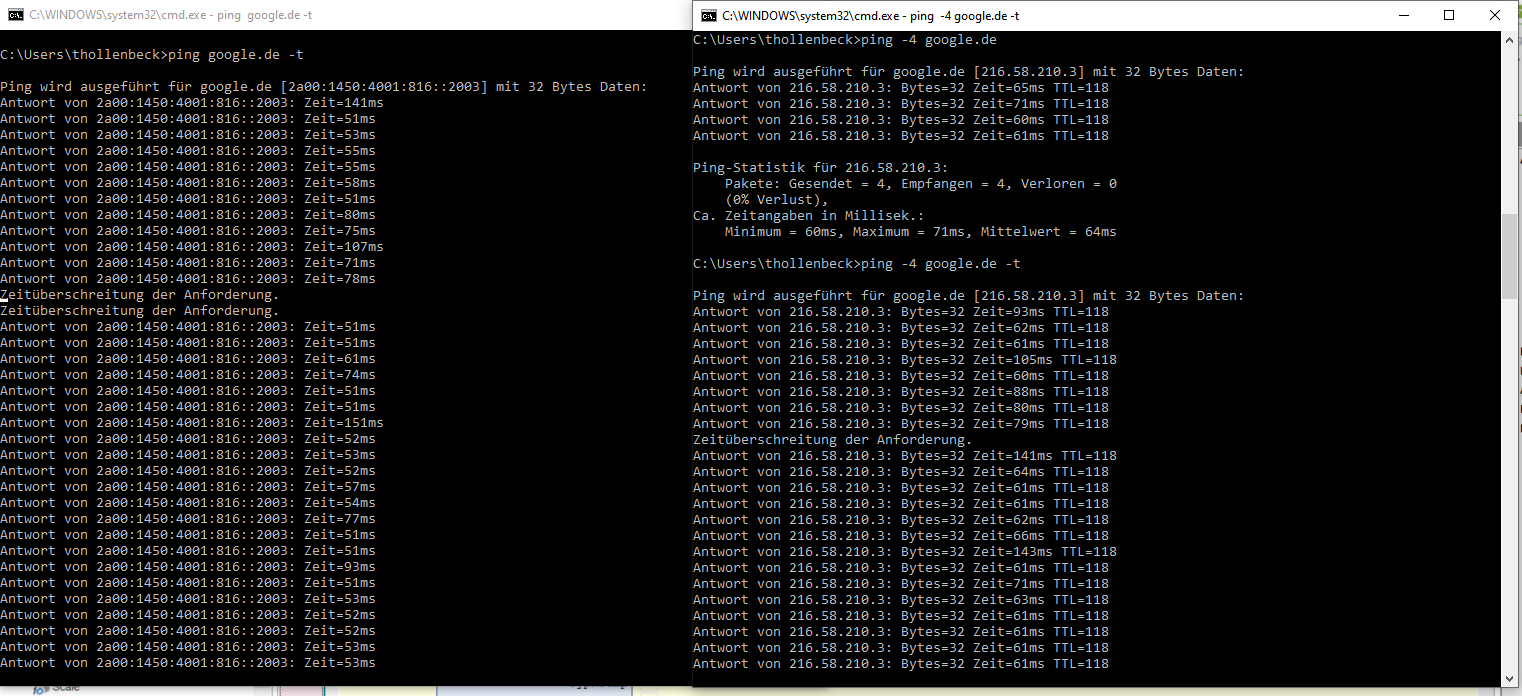
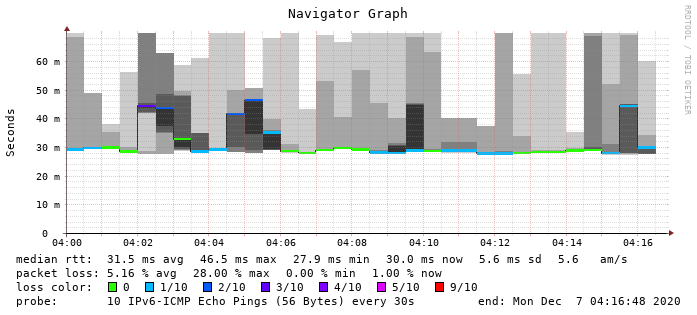
es scheint als gibt es im IPv6 nen Blinker - da wird irgendwas alle 10 Sekunden hin und her geschaltet und ein Pfad ist tot - Mir ist das aufgefallen weil DNS UNGLAUBLICH langsam war und ich dann mal den IPv6 Nameserver befragt habe und der eigentlich ständig in einen Timeout lief:
flo@p4:~$ ping 2001:bf7:1310:11::67:1
PING 2001:bf7:1310:11::67:1(2001:bf7:1310:11::67:1) 56 data bytes
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=1 ttl=64 time=203 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=2 ttl=64 time=79.3 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=3 ttl=64 time=51.10 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=4 ttl=64 time=57.3 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=5 ttl=64 time=24.7 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=6 ttl=64 time=25.7 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=7 ttl=64 time=28.2 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=8 ttl=64 time=26.8 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=9 ttl=64 time=27.10 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=20 ttl=64 time=30.0 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=21 ttl=64 time=26.8 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=22 ttl=64 time=26.4 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=23 ttl=64 time=24.5 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=24 ttl=64 time=27.6 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=25 ttl=64 time=53.9 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=26 ttl=64 time=45.0 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=27 ttl=64 time=42.8 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=28 ttl=64 time=47.4 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=29 ttl=64 time=49.5 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=45 ttl=64 time=43.7 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=46 ttl=64 time=47.9 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=47 ttl=64 time=43.6 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=48 ttl=64 time=46.5 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=50 ttl=64 time=39.2 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=51 ttl=64 time=27.1 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=52 ttl=64 time=25.2 ms
64 bytes from 2001:bf7:1310:11::67:1: icmp_seq=53 ttl=64 time=24.5 ms
^C
— 2001:bf7:1310:11::67:1 ping statistics —
56 packets transmitted, 27 received, 51.7857% packet loss, time 743ms
rtt min/avg/max/mdev = 24.463/44.304/202.709/33.798 ms
Die Pingen ins Inet, bzw. sich gegenseitig an. Je auf v4 und v6. Irgendwo bleibt dort noch etwas hängen.
Ob man per Wireshark etwas heraus finden kann?
Bin gerade am überlegen was der nächste sinvolle Schritt aus dem Netz heraus währe um den Fehler einzugrenzen. Evtl. mal im L2TP Netz testen. Falls es dort sauber läuft noch ein Grund schleunigst zu wechseln.
Vom allgemienen empfinden wenn ich mich im Netz bewege fäält der Paketloss hauptsächlich bei SSH auf. Eine Datenübertragung ist wenn man es nicht weiß nur gefühlsmäig gering eingeschränkt.
Dein Monitoring sieht aber auch bei v4 noch wesentlich besser aus als meins.
Habe gerade mal den Laptop etwas mitlaufen lassen, um noch einmal von anderer Hardware zu sehen ob dort auch Verluste auftreten.
Da fehlt auch immer etwas.
Das war bis eben auch ausschließlich direkt von der VM auf meinem Server bei Hetzner — mehr so ein Kontrollwert.
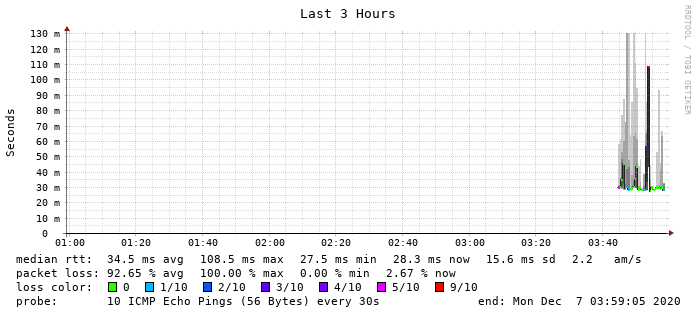
Erst nach laaangem Debugging habe ich Smokeping dazu bekommen, über ip netns exec auch Daten über die Gateways zu sammeln — hier v4 über legacy-ber01 (GW02):
Und hier v6 über das Legacy-GW 01, ebenfalls legacy-ber01-VM:
Note to self: »Smokeping« läuft unter dem User »smokeping«, ip netns exec benötigt root-Zugriffsrechte. Alles trivial, wenn man das erstmal realisiert hat *sigh*.
Nachdem das netns-Problem gefixt ist, wird der Smokepig noch weitere Ziele bekommen, um die Probleme besser eingrenzen zu können.
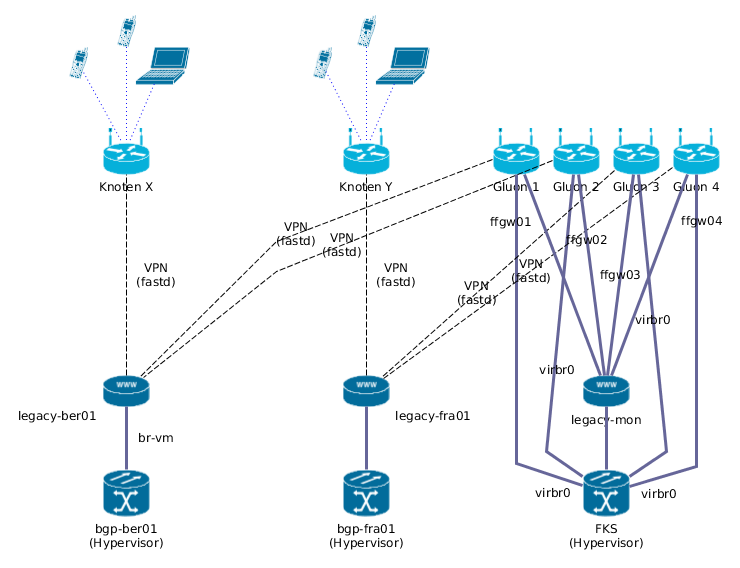
Zur Erinnerung, das Testsetup besteht aus 1 Linux-VM, die hinter nun 6 Gluon-VMs (ffgw0[1234], muer0[12]) hängt, zu jeder Gluon-VM gibt eine Linux-Bridge auf dem Hypervisor Zugang, was in der Linux-VM jeweils als Ethernet-Interface aufschlägt. Über »Network Namespaces« werden die 6 Verbindungen zu den Gluon-VMs separiert, sodaß von der einem Linux-VM 6 Client-Verbindungen simuliert – und diese entsprechend getestet – werden können:
Habe gestern eine für mich interessante Entdeckung gemacht.
Was ist passiert?
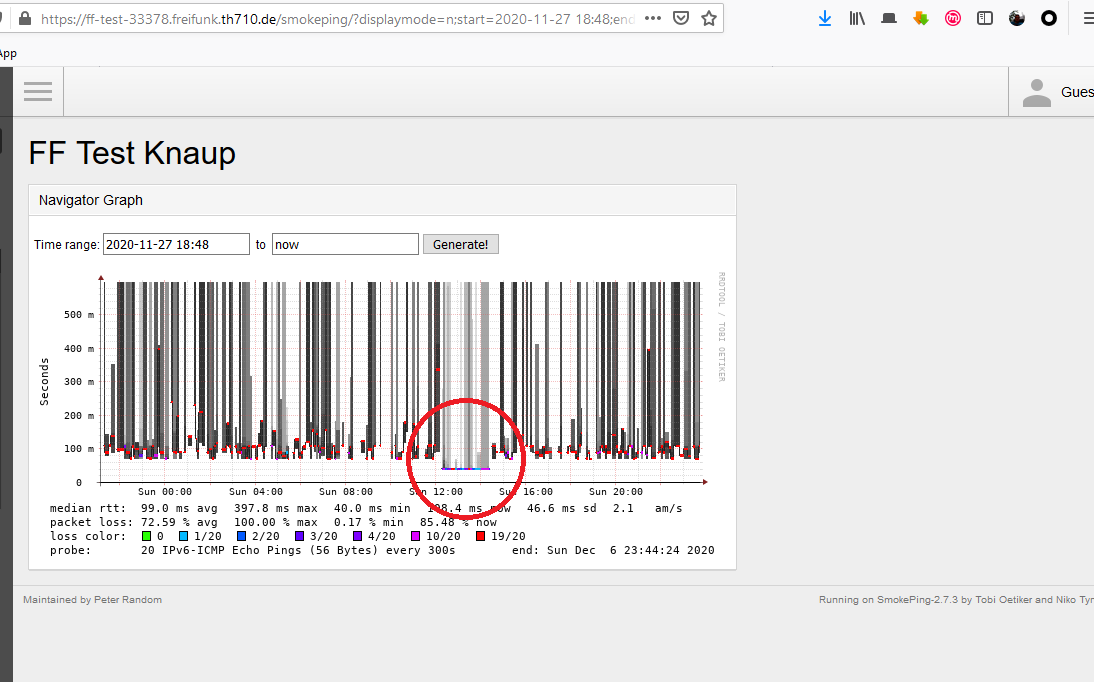
Ich habe den Knoten bei mir in der Firma von einen VDSL100 Anschluss (der einen relativ hohen Ping hat (ca. 40ms), (falls wer fragt woran es liegt, der hat eine Statische IP). Auf ein 2mbit/s DCIP gelegt. (Ping 8-10ms).
Und siehe der Paketverlust halbiert sich ca. . (Der Test, der in dem Graph von Smokping gefahren wird ist aber ein Härtefall, da ich im FF Netz von RPI - Knoten - VDSL - Telekom - VDSL - Knoten -RPI pinge.)
Es gibt zwei Punkte die an dem Anschluss anders sind. Die MTU ist bei einem DCIP 1500 und die Pingzeiten sind auch sehr nidrig und stabil.
Ich bin gerade am überlegen wie ich weitermache. Mein Bauchgefühl sagt das es eher die Pingzeiten sind als die MTU woran es liegen könnte.
Nein, ich war auf unterschiedlichen. Ich habe aktuell auf den Knoten keinen SSH Zugriff um die Server Adresse manuell zu ändern.
Aktuell nutzt der KNoten Knaup
217.197.83.191
02:ca:ff:ee:00:23
und in Wiedenbrück ist die GW
02:ca:ff:ee:00:20
Da ich auf beiden Paketverluste in Smokeping sehe, glaube ich nicht das es an einer speziellen GW liegt. Das Problem tauch überings auch bei IPv4 auf.
Ich werde die verschiedenen GWs mal durch testen.
Aber auf der Monitoring seite sind ja auch auf allen GW Paketverluste zu sehen. Auch wenn nicht so hoch. Aber die Spiegeln aus meiner Sicht ca. das nach was ich auf der Standleitung hatte.
Was mir gerade noch aufgefallen ist. Die Knoten habe ich gerade von extern aus angepingt. Bei ihnen habe keine Dramatischen Verluste. Auf die RPIs dahinter schon. Zur Info der Anbindung, sie hängen entweder direkt am Knoten, oder über einen einafachen Nicht konfigurierbaren Switch am Knoten.
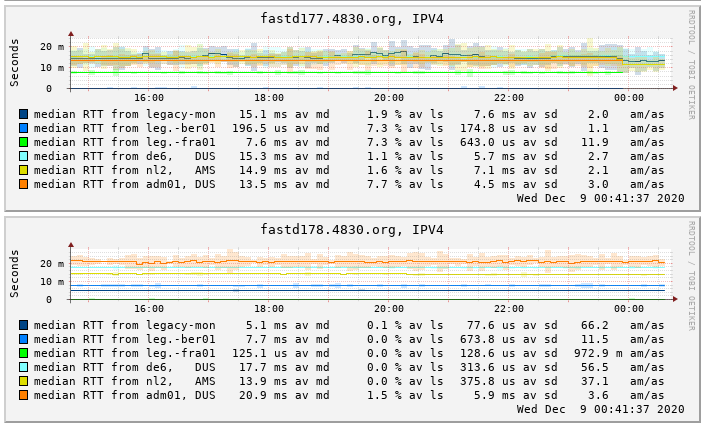
fastd176.4830.org und fastd177.4830.org lösen auf auf IP-Adressen von IN-Berlin, die auf unserem Server in BER aufschlagen und über IN-Berlin auch wieder rausgeroutet werden.
Die Erwartung war, daß wir dadurch von Routingproblemen in/mit unserem AS unbehelligt bleiben; unsere beiden mitgenutzten /24 sind ja über alle Standorte verteilt. Den Zahlen nach … war das keine so richtig gute Idee
So ganz weiß ich noch nicht, was ich damit anfangen soll; die IPs aus unserem AS in FRA sind jedenfalls verlustfreier zu erreichen …